The 10 short posts threaded into this issue — the atoms behind the weekly read. Read the full issue →
AI-Native GovernmentTrust in Process
🔎 A benefits agency stands up an AI system to help decide claims. It is fast, and most of the time it is right.
Then one denial gets appealed, and the agency is asked to explain that single decision. What the system did on that file. When. On whose authority. On what basis it was allowed.
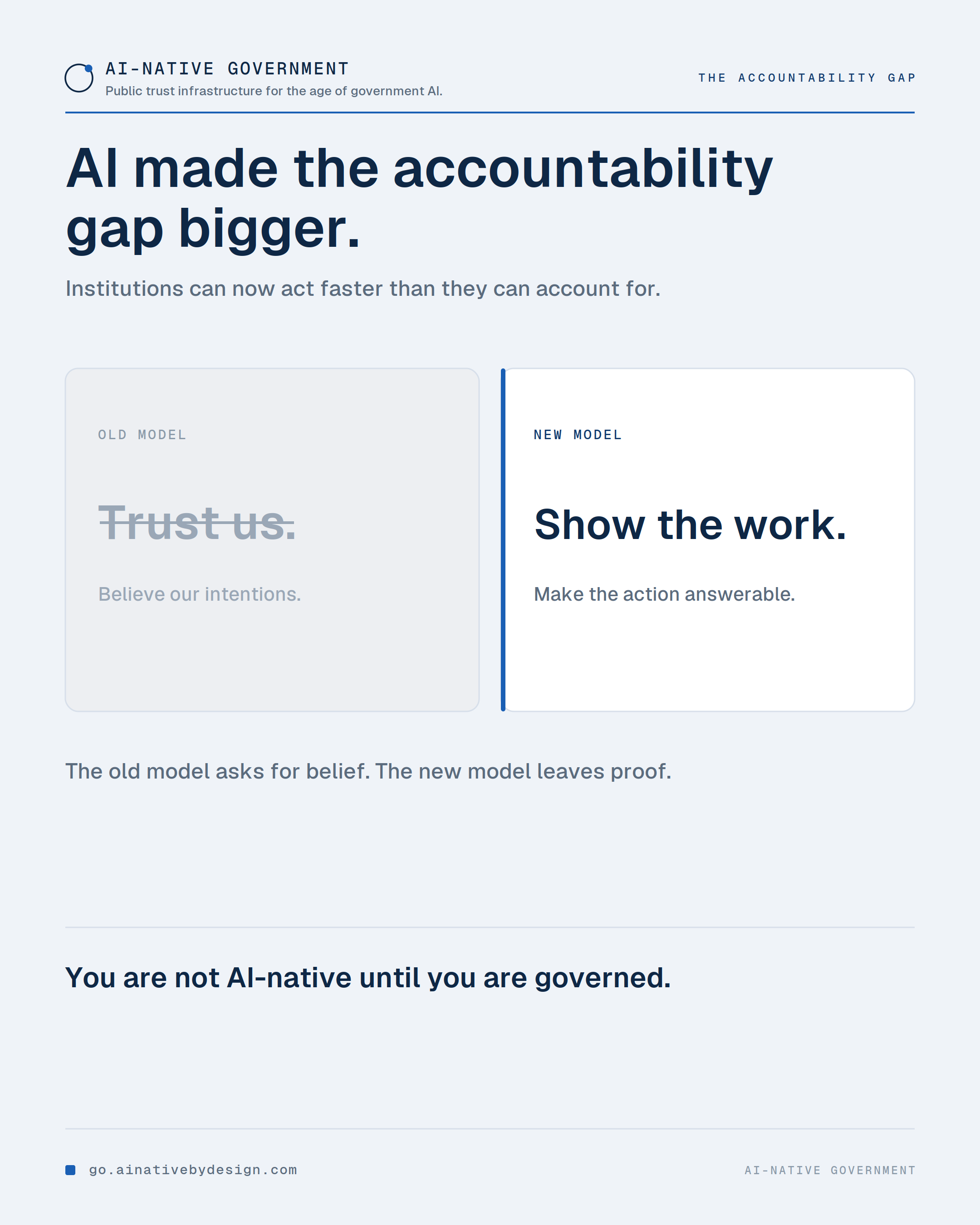
If answering takes a week of digging through logs and inboxes, the agency does not have an AI problem. It has an accountability problem, and AI made it bigger and faster.
That gap, between what an institution does and what it can account for, is public trust infrastructure. Closing it is the work.
You are not AI-native until you are governed.
AI-Native GovernmentTrust in Process
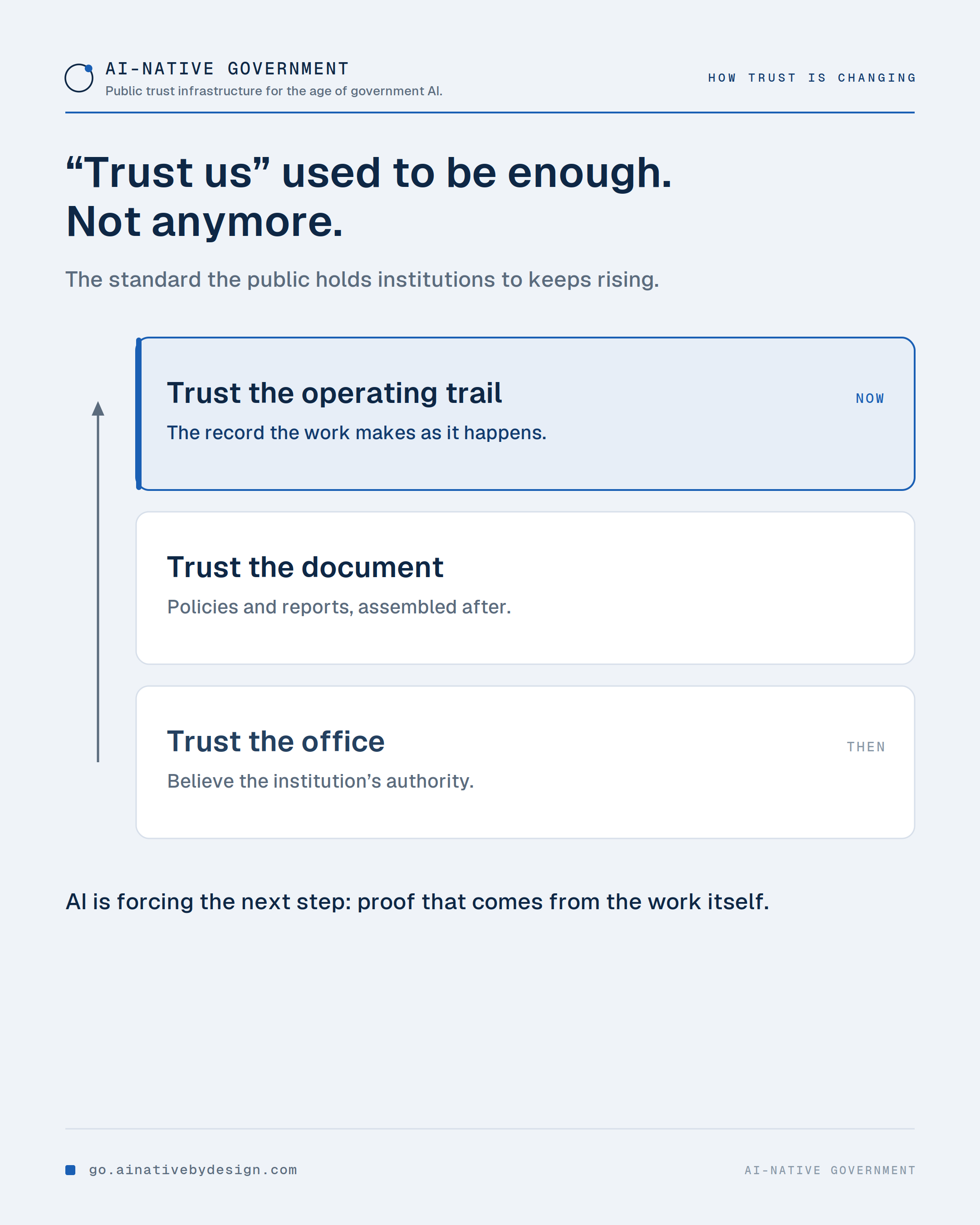
🧭 For a long time, public institutions could ask people to trust the office. Then the standard rose, and trust moved into documentation: policies, reports, audit files assembled after the fact.
AI raises the standard again. When a decision passes through models, vendors, rules, approvals, and exceptions, a story reconstructed afterward is not proof. The work has to leave its own trail as it happens.
That is the shift this page is about. Not "we followed the policy," but "here is the record of what happened, made by the work itself."
The newest tool is not the public-sector AI question that matters. This is: which of your workflows can still be trusted when someone asks.
AI-Native GovernmentThe Four Questions
✅ Pick the last decision your agency made with help from AI. A claim, a flag, a routing, a score. Now try to answer four questions about it without reconstructing the story afterward.
What happened. When it happened. Who set the rule. Why it was valid.
Answer all four and the decision is governed. Miss one and it is exposed. These are not abstract. They are the same questions an auditor, an appeals board, or a reporter will ask, and they are the test every governed workflow has to pass.
Most agencies can answer two of the four today. The fourth, why it was valid, is usually the one missing.
AI-Native GovernmentThe Ladder
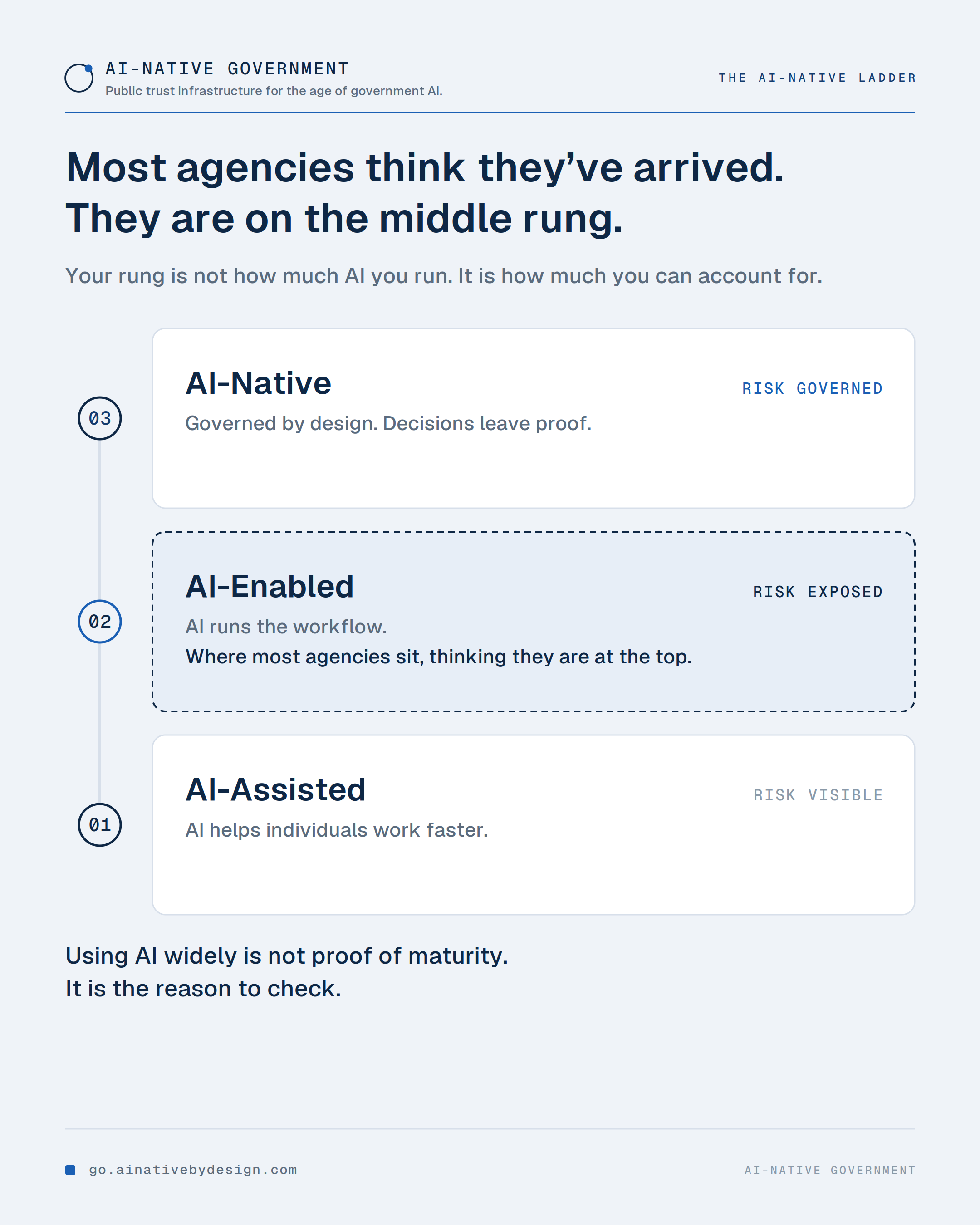
⚠️ The most dangerous agency is not the one barely using AI. It is the one using AI widely and mistaking deployment for maturity.
That agency is on the middle rung. AI-Enabled: the work runs through AI, but the institution cannot fully account for it. Enough AI to create real consequences, enough controls in the well-run corners to feel covered.
What moves an agency up is not how much AI it runs. It is how much of it can be accounted for. Which is why an agency can have AI in every division and still be exposed.
If your agency uses AI widely and feels like it has this handled, that feeling is the thing to check.
AI-Native GovernmentThe Four Questions
🧾 A paper trail explains what people believe happened. An operating trail shows what happened as the workflow moved: the rule that was active, the data used, what the AI recommended, who approved, what exception triggered, what record was written.
For government AI, documentation assembled later is not enough. The work itself has to leave the trail.
That is what makes review possible. That is what makes correction possible. And it is the difference between defending a decision and being able to show it.
AI-Native GovernmentThe Field
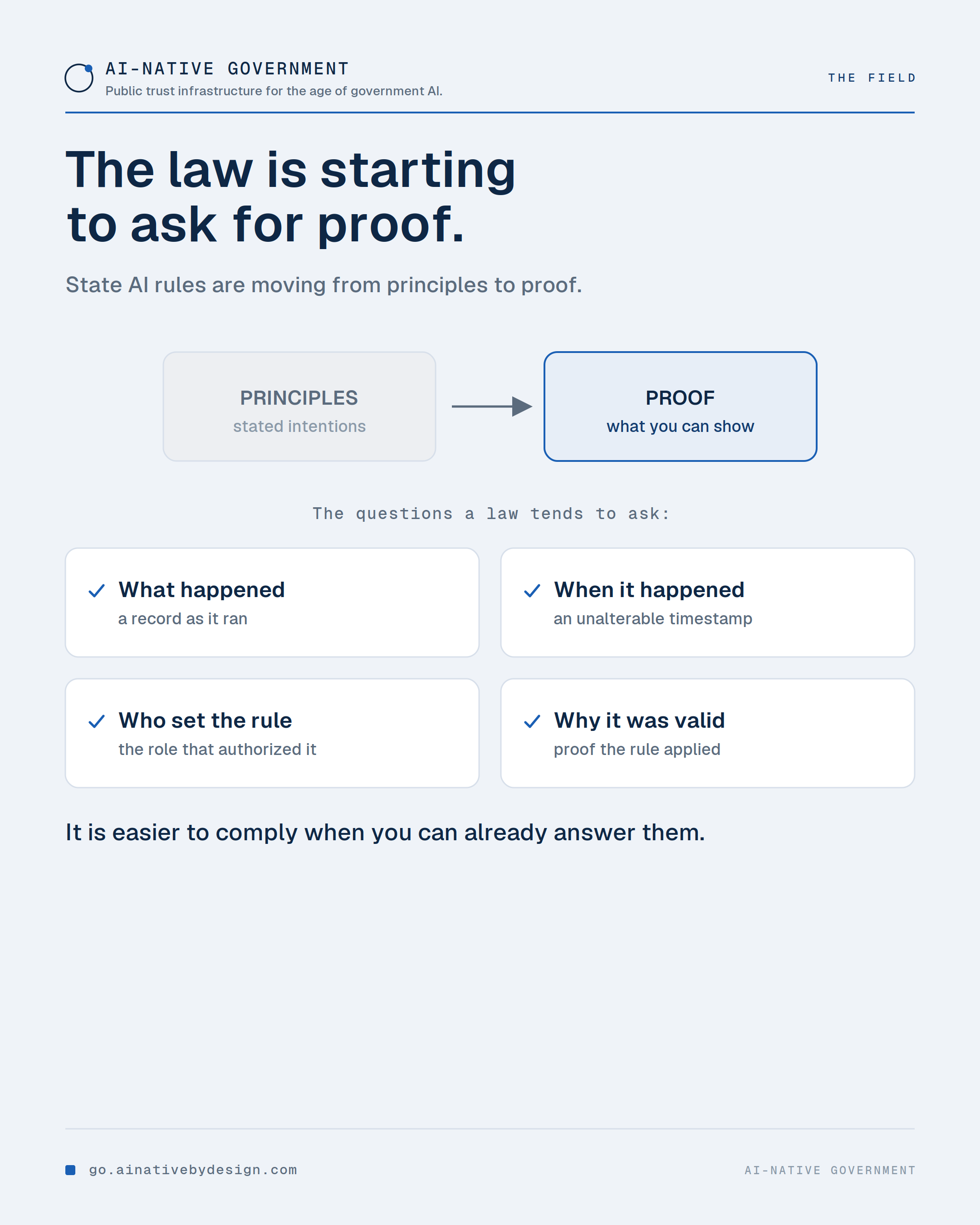
⚖️ Texas now has a law that places transparency and governance obligations on public-sector AI use. Set the politics aside, this is not a partisan point. The signal is the direction: accountability for public-sector AI is moving from best practice to legal requirement.
The agencies ready for that shift are not the ones with the most AI. They are the ones that can already show what their AI did, when, on whose authority, and why it was allowed.
Laws like this tend to ask the four questions. It is easier to comply when you can already answer them.
AI-Native GovernmentThe Four Questions
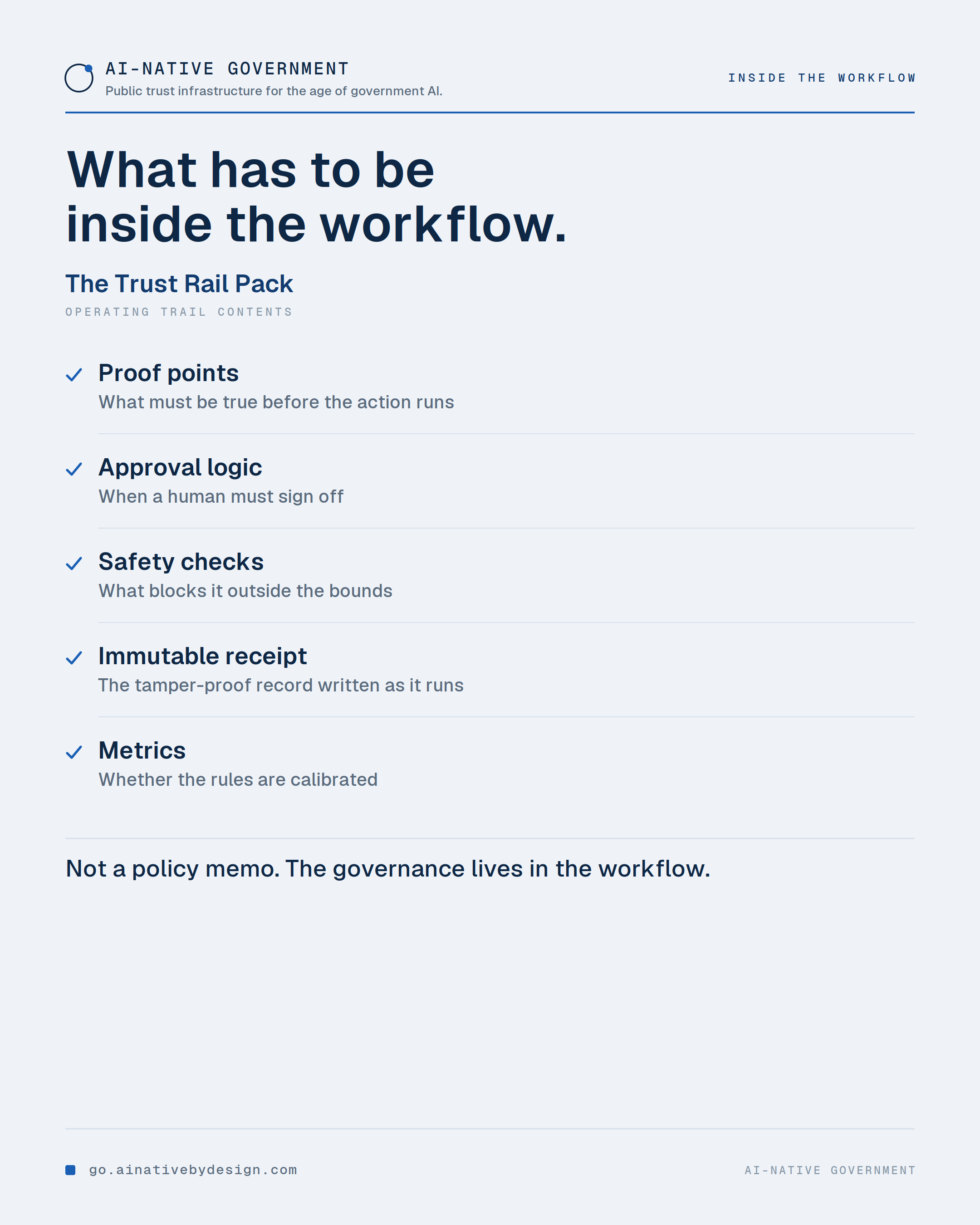
🔧 A policy is not a trust rail. A meeting is not a trust rail. A trust rail is something built into the workflow that governs the work while it runs.
A Trust Rail Pack has five parts: the proof points that must exist before an action executes, the approval logic that pauses it above a threshold, the safety checks that block it outside bounds, the immutable receipt written at the moment it runs, and the metrics that show whether the rules are calibrated.
This is where many AI projects are too thin. They have a use case, a vendor, a pilot, and a policy memo, but not enough governance inside the actual workflow. That gap is the risk.
AI-Native GovernmentThe Vendor Problem
📝 Most government AI is bought, not built, and that is normal. But accountability cannot move outside the institution. The public experiences the outcome as government action, whoever supplied the model.
So before scaling a vendor-enabled workflow, the questions are concrete.
Can you inspect the operating trail?
Can you export the records?
Can you see when a model or rule changes?
Can you audit exceptions?
Can you explain a decision without the vendor?
Can you correct harm if something goes wrong?
Procurement is not just buying capability. It is protecting institutional responsibility, and that has to be written into the contract before you sign.
AI-Native GovernmentThe Ladder
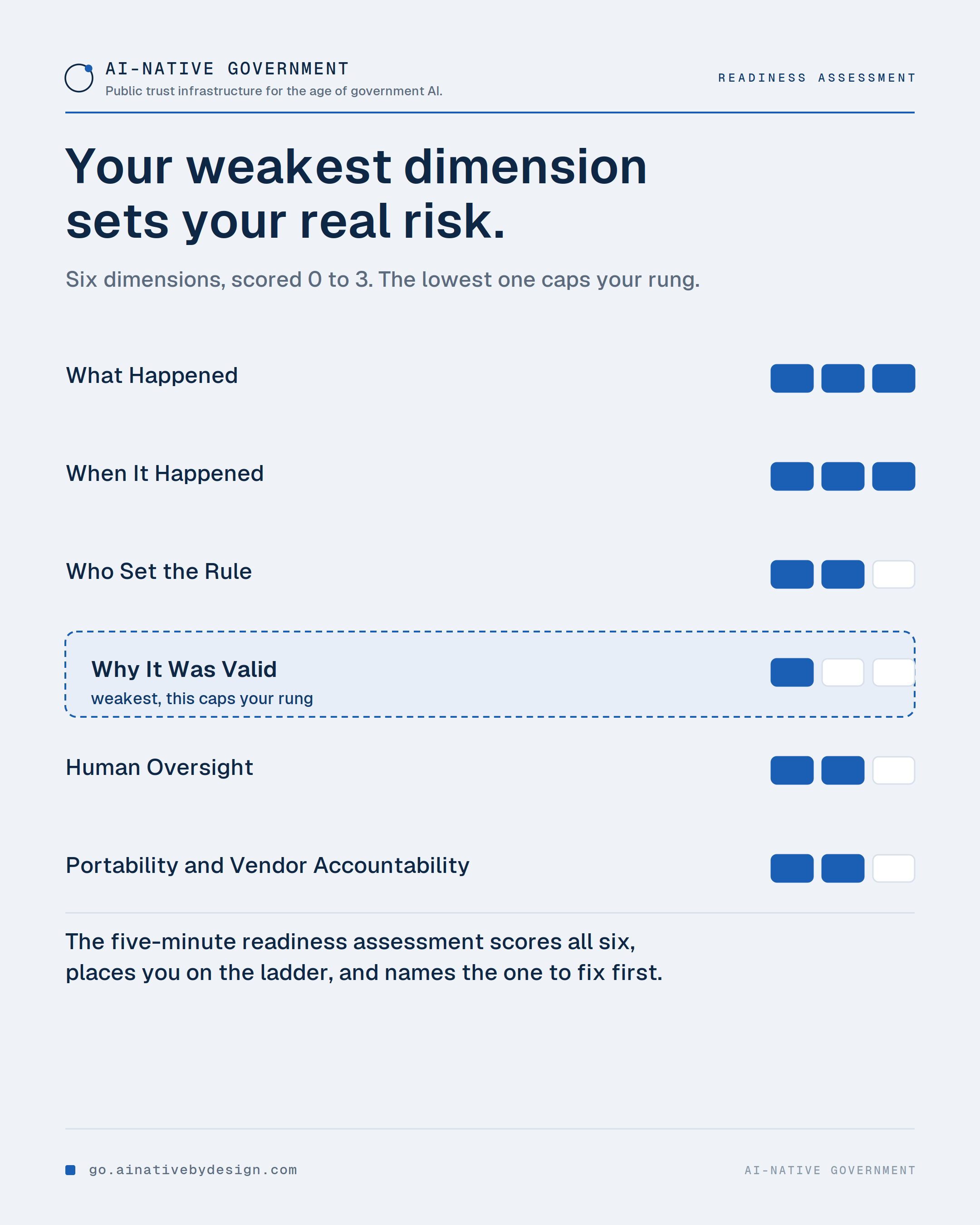
📊 Most AI readiness conversations ask whether you have a strategy, executive support, policies, tools, training. Those matter. They also miss the sharper test: can the AI-shaped workflow actually be governed.
A workflow can look mature from the outside and still fail it. No clear operating trail. Weak exception handling. Vendor-controlled records. No way to explain what happened without reconstruction.
That is why the weakest part matters most. In government AI, one ungoverned dimension can define the whole risk profile, no matter how strong the others are.
The five-minute readiness assessment scores your agency on six dimensions, places you on the ladder, and names the one to fix first. Take the free assessment →
AI-Native GovernmentTrust in Process
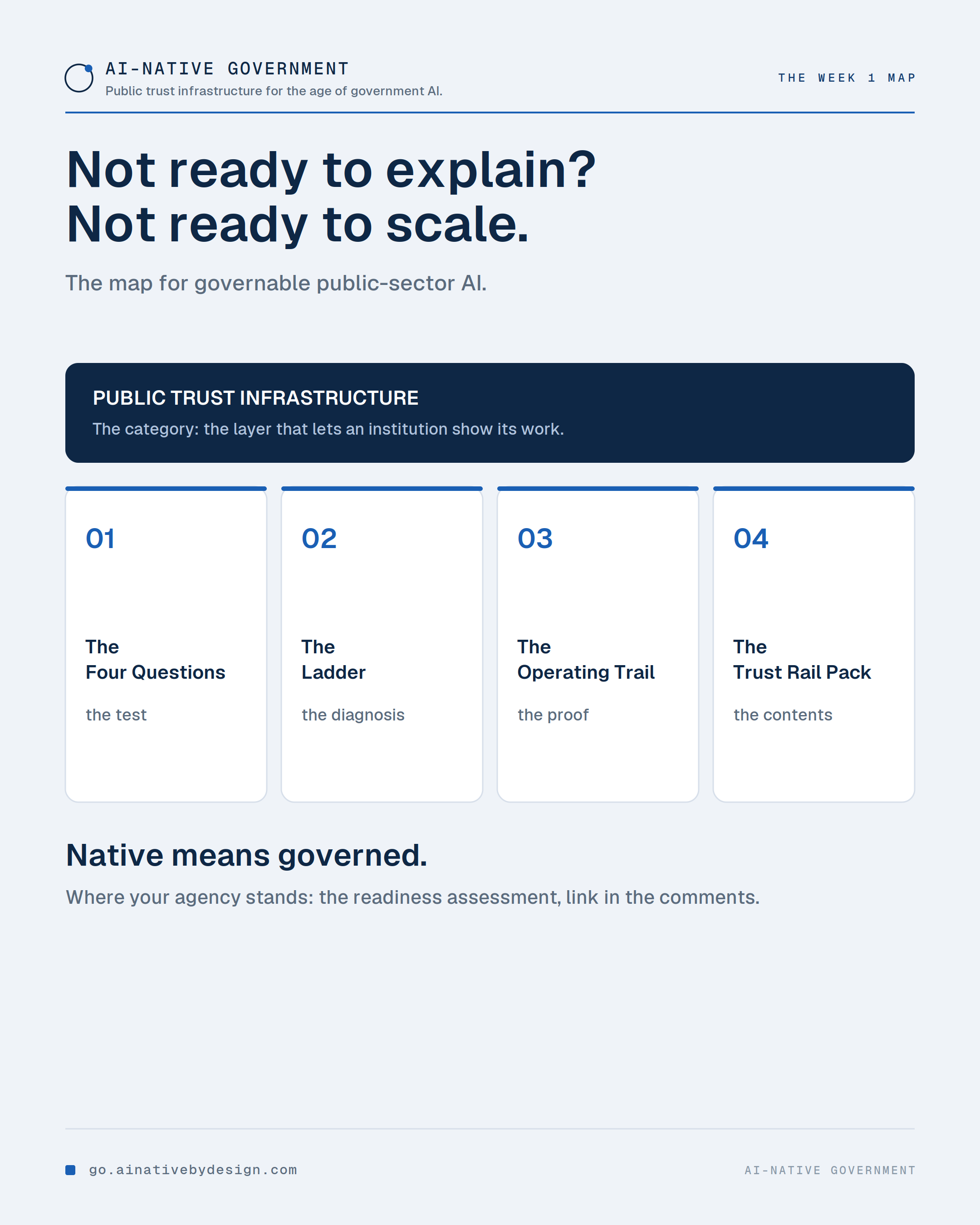
🗺️ The one rule under everything this week: an AI workflow you cannot review, correct, and explain is not ready to scale.
Here is the map for getting there. Not AI hype, not tool lists, not procurement headlines.
Public trust infrastructure is the category: the layer that lets an institution show its work. The four questions are the test. The ladder is the diagnosis, and the rung is set by governance, not tool count. The operating trail is the record the work makes as it runs. The Trust Rail Pack is how that governance lives inside the workflow.
Government AI should not just be faster. It should be governable. Native means governed.